Projects for You
If your project is one you will be undertaking with or without help, just define the scope of your collection and post on the forum under Projects in the Works so others will not unknowingly duplicate you efforts, or contact you if they would like to assist. Possible topics are nearly limitless. A collection of How to books would be worth doing, which could even be subdivided further (computer related ebooks are quite abundant so I would have a separate collection for them). There may be enough books for other separate collection, perhaps a gardening how-to, or home repair how-to collections. The problem of defining catagories to avoid overlap is one that might be discussed on the forum.
PG Reorganization Project
Overview
I have one major project to propose: the reorganization of the Project Gutenberg (PG) ebooks. Since its beginnings in 1971, PG has collected over 27,000 ebooks (over 21,000 in English) and it is likely that that just about every book written prior to about 1929 that might be of interest has been or will be added to the collection. So PG is a good starting point. PG Australia has books up to the 1950's as copyright runs out sooner there than in the USA. Many books written in the past 50 years have been released for legal sharing even though they remain copyrighted. Some authors today release their new works for download and ask for a donation if you like the work.
So let's call this the PGRP (PG Reorganization Project). The goal is to assemble an html only collection of all PG books. Unlike plain text, html can be formatted for readability. This is very important. We want to encourage reading and one way is to do so is to make ebooks flexible in format (the reader can select the font, change the size of font, line spacing, colors) with titles and headings in large print, and perhaps a table of contents with hypertext links. Many old books were beautifully formatted and lavishly illustrated. Many of these have been scanned to html with all illustrations included. A lavishly illustrated Mark Twain classic is vastly more readable than a plain text version, and an ebook version with illustrations is likely to be even more desirable than any copy you might find in a library or buy new.
Why html? This is an editable format, both text and graphics can be edited, and most formats can be converted to it. Html is a univeral format which can be converted to most other formats (html is not compressed and often consists of many html files and many graphic files, so converting to a compressed all-in-one file like .prc is especially desirable). Future ebook formats will surely support conversion from html. Our goal should be to collect ebooks having the best format available which means getting away from plain text files.
PG recognizes the value of html versions as almost all new additions are in both html and txt formats, and 9,000 of their English books are already in html, which means about 12,000 are not. Fortunately there is software that does a reasonable job of batch automatic conversion from PG txt to html. Minor editing would still be desirable, but the bulk of it can be done for you. Still, 12,000 is a lot of books, but if 120 voluteers did 100 books, the project could be done in short order.
The other problem is PG names books by number inside number-named folders in the order that they were added to the collection. Access, finding a book, depends on an index, as the actual collection on disk is unbrousible. This way of organizing the collection, by acquisition number, makes updating the index file difficult. Here's how I propose the collection be organized: For fiction titles, create folders for each author, last name first. Within which are the author's work(s) having a folder name starting with year of publication, author's last name, and then title. So there would be a folder call "Twain, Mark, 1835-1910" (the folder name is copied from the PG index) within which you would find:
1867 Twain, Celebrated Jumping Frog of Calaveras County
1869 Twain, Innocents Abroad
1871 Twain, Roughing It
1876 Twain, Adventures of Tom Sawyer
And so on. Note that each are folders containing one or more html files, .prc versions, and one or more (possibly hundreds) of illustrations. Adding the year a work was written adds significantly to the information about it as all works are works in time. Finding the date will mean doing a google search and in a few cases using the year of the authors death if publication date is unknown (so 1787- would mean before 1787 as we can assume the work could not have been written after the author's death). In some cases your best guess may be needed, but overall having a date should be well worth the added effort. Also, by default, the collection will be sorted by year. It is easy to get the names from a directory and to sort by second word (by author) or the third (the title). so title/author indexes are easy to generate and update. If you know the author's name, you will be able to go to the book you want without even using an index, printed or in a file on disk.
How to obtain the files
Let's say you want to do 100 books. First look on the forum and see how far the group has gotten. Let's say the last person signed up for books 1500-1599. This means you need to take books 1600-1699, so you post your intention to convert, or edit the books as needed. You will not know what books are in this range, but obtaining (some of) them is easy thanks to the following link: Create a Custom CD or DVD
At this site you enter a range (1600-1699) for the files you want, a name for this collection (ebooks1600to1699), and a name for the file they will create for you (1600to1699.iso). You will be sent a link to download the books. It is important to get "zip/html" versions first, then "html" in case there is no zip version (it is the zip versions only that contain graphics if any). Finally, if no html version exists, get the zip/txt version (available for all PG books).
What you see:
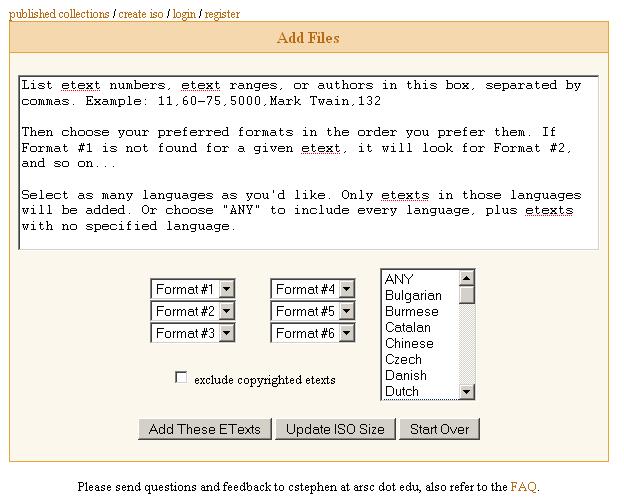
What you need to enter:
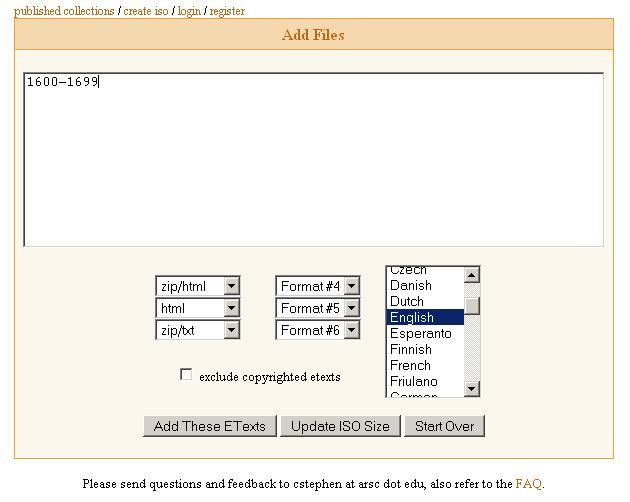
Then click "Add These ETexts" and wait.
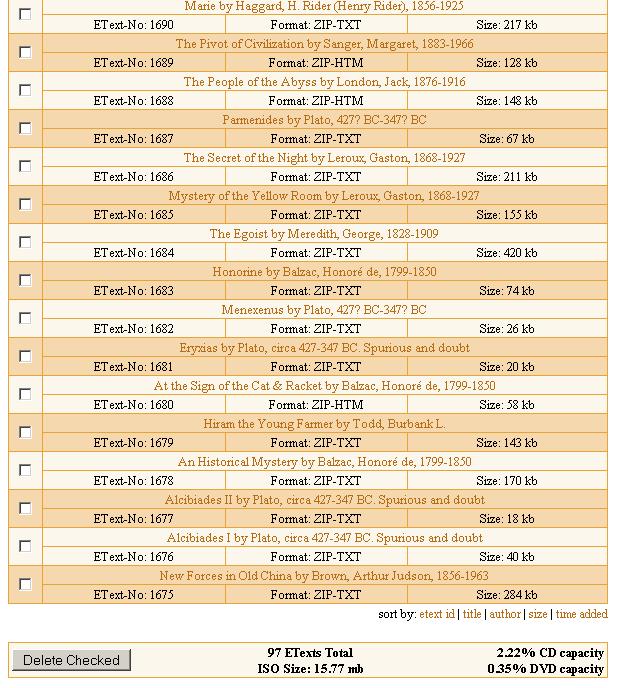
Note that you are three less than 100 as some numbers are skipped. Also most of the works scanned early on are still txt only, and will need to be converted to html.
Look at the small top menu for "create iso" and click it:
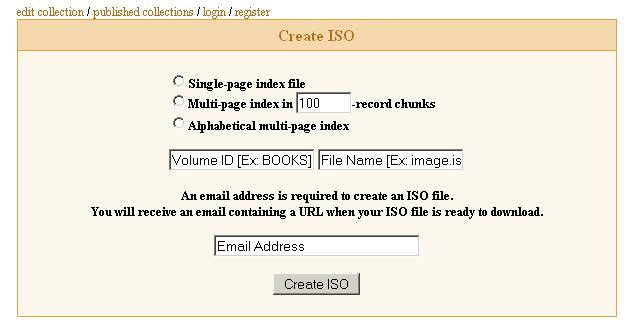
Fill out this page:
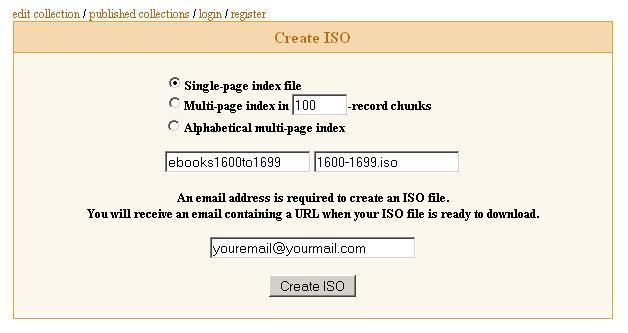
And click "Create ISO" and you're done apart from waiting maybe a half-hour or so for the email link. Unfortunately, the ISOs I have received so far have not included all the files in the list that was generated. There seems to be a bug in the works, so either wait for it to be fixed or figure out a work around. Even with missing files, the index that comes with the iso is complete and is useful when creating author folder names.
The file you get is an ISO file and you will need software to "mount" it. For this you can pick from a number of programs if you don't already know how to do this. After mounting the ISO to a virtual drive, copy all the folders to a temp folder on your hard drive for editing. The files themselves are zipped and you'll need software to upzip them. If you don't already have this ability, try 7-Zip which can also unpack .rar files that you may encounter.
Now go to the temp folder and right click on it instead of opening it. Select "Search" and then search for "*.*" (or just press Enter) to find all the zip files. You need to have a detailed view so go to View and select "Details" if you need to. Click on "Type" to sort by file type. Scroll down below the folders and you'll see all the files. Look for the first zip file and click on it to highlight it. Scroll to the last one, hold Shift key down and click on it to select all .zip files. Right click on one and select "Cut" then Paste to a separate folder. Select all the zip files and right click on one, then look for the 7-Zip tab (if you're using it) and click on "*/" to extract each zip file to a separate folder. Again right click on the folder that contains all the new folders just created, select "Search" and sort again by "Type" to see what files you have. If all files are either .txt or .html then you just need to select all the txt files and copy/cut them to a new txt folder (one not inside the current temp folder, then select all of the html and put them in a final html folder. If there are any graphic files or parts of html files (perhaps named p1.html, p2.html, and so on) then you need to select them and put each in a new folder within the final html folder. First sort by clicking on the "In Folder" tab, then look for the first non-txt/html file. The html file above it, and all the non-html files below it, need to be cut and put in a separate folder as they are all part of one illustrated book (the graphic files will end in .gif, .jpg, or .png).
So now you have all the html ebooks in a final folder either as separate files or in a folder with multiple files. This is when you can rename all the books using the year/last name/title format. The books inside a folder should be in a folder having the exact name apart from the ".html" ending, but do not rename the split html versions. You can then create folders for each author and drop the ebooks in the appropriate one.
This leaves all the txt files in one folder. Now just run Gutenmark (a Project Gutenberg txt reformating "prettifier" program that converts plain txt files to html) using batch conversion. Make sure "Use symbolic entities?" under "HTML Output?" is checked on, and select "Split at headings." Convert to the html folder and rename folders. A single file version is also created, just drag and drop into the folder containing the split version. The single file version should have the same name as the folder, but don't rename the split version. You could make a copy of the first "000" file and give it a meaningful name if you wish. Consider that some txt file are best not split up, so if the split version doesn't come out or seems unnecessary, then delete it.
Now go through and open each file using your favorite html editor (don't have one? get the open source editor KompoZer). Just look the book over and make a few adjustments. Often the PG header can be condenced, converted to small print, or even just reduced to: Project Gutenberg eBook #1677 or whatever number it is). Check at the end of the text as there may be several pages of the ubiquatous, excessive license verbage that could (perhaps should?) be eliminated.
Finally, since the Mobipocket format is the most widely supported ebook reader format, let's help make it a format all future ebook readers will have to support if they hope to become popular. Just get and open Mobipocket Reader, select all of the single html files as a group and drop them on the Mobipocket Reader or do one at a time as needed. The illustrated html files in folders can also be dropped on Mobipocket Reader, but only if there is a single html file. If there are more than one, use Mobipocket Creator, select the first, then Add the others in the appropriate order.
Now you should have a folder containing author folders within which are folders containing html ebooks. Zip or rar the folder (Project Gutenberg eBooks 1600-1699 in HTML & PRC.rar) and create a torrent called "Project Gutenberg eBooks 1600-1699 in HTML & PRC.rar.torrent" and upload to Mininova or other site, then put a link on the forum. They can then be downloaded by members and dropped on the master collection everyone should already have to update it.
|
